Publications
Selected Publications (*Corresponding Author)
-
TourMLLM: A Retrieval-Augmented Multimodal Large Language Model for Multitask Learning in the Tourism Domain
,
H. Yamanishi, L. Xiao* (corresponding author), and T. Yamasaki,
ACM ICMR, pp. 1654–1663, 2025, Best paper award!
News page!
Fig. 1. Overview of TourMLLM: retrieval-augmented pipeline for tourism tasks. -
A Multihead Continual Learning Framework for Fine-Grained Fashion Image Retrieval with Contrastive Learning and Exponential Moving Average Distillation
,
L. Xiao and T. Yamasaki,
IEEE Transactions on Multimedia, pp. 1-10, 2026.
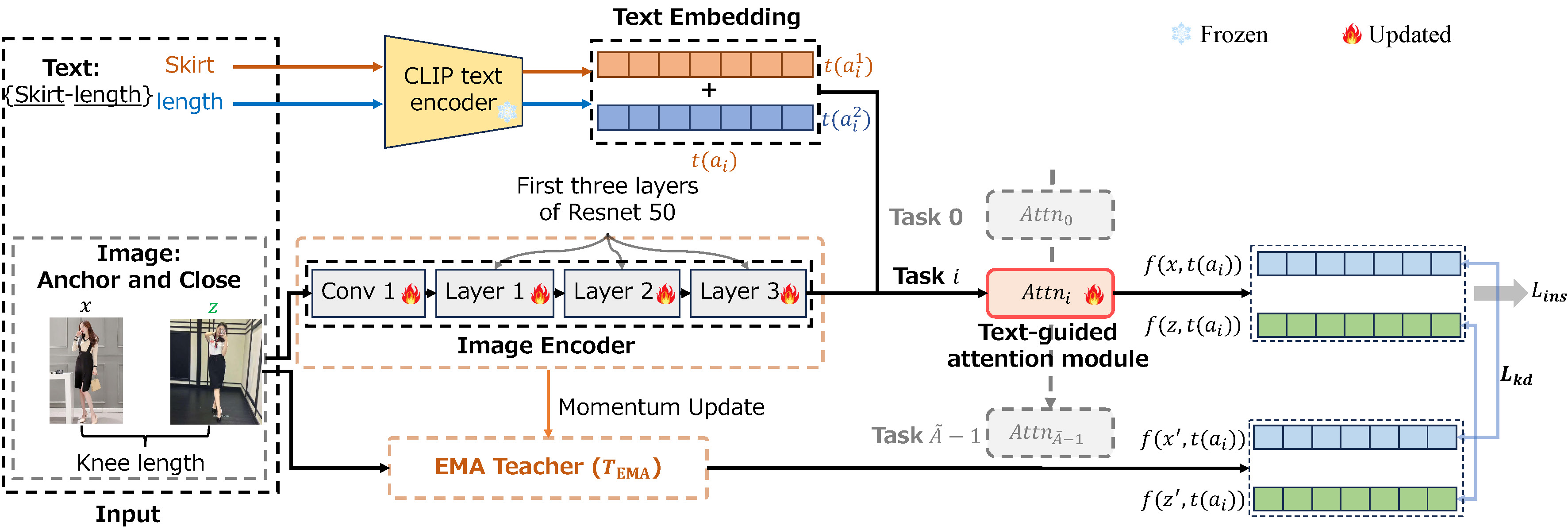
Fig. 1. Detailed pipeline of the proposed MCL-FIR model. -
Multi-level Knowledge Distillation for Fine-grained Fashion Image Retrieval
,
L. Xiao and T. Yamasaki,
Knowledge-Based Systems, vol. 310, p. 112955, 2025.
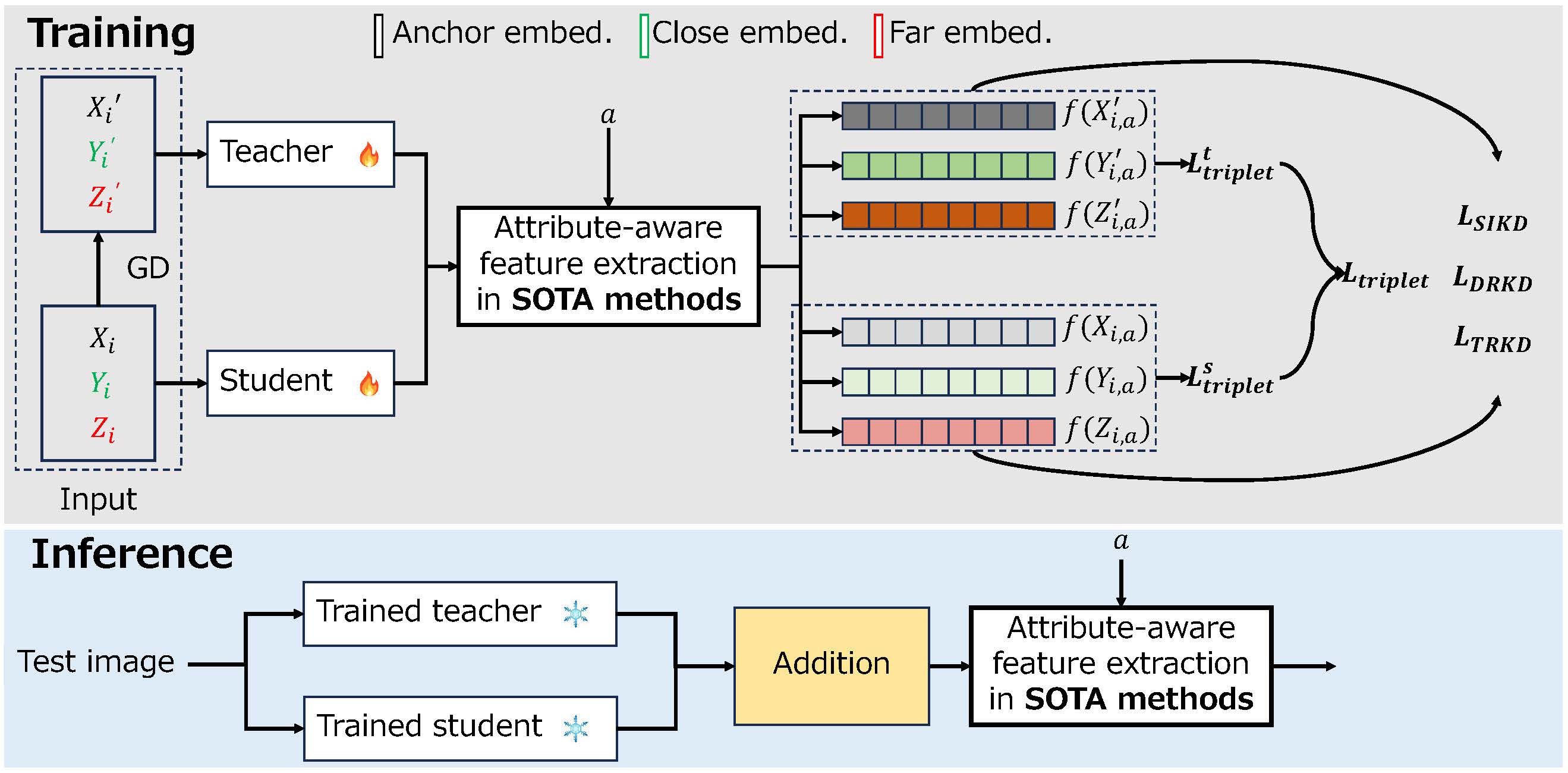
Fig. 1. Details of the proposed MKD. -
MAction-SocialNav: Multi-Action Socially Compliant Navigation via Reasoning-enhanced Prompt Tuning
,
Z. Wang, X. Zhang, Z. Liu, T. Kawabata, D. Song, X. Xiao, and L. Xiao*,
IEEE Robotics and Automation Letters (RA-L), vol. 11, no. 8, pp. 9747-9754, 2026.
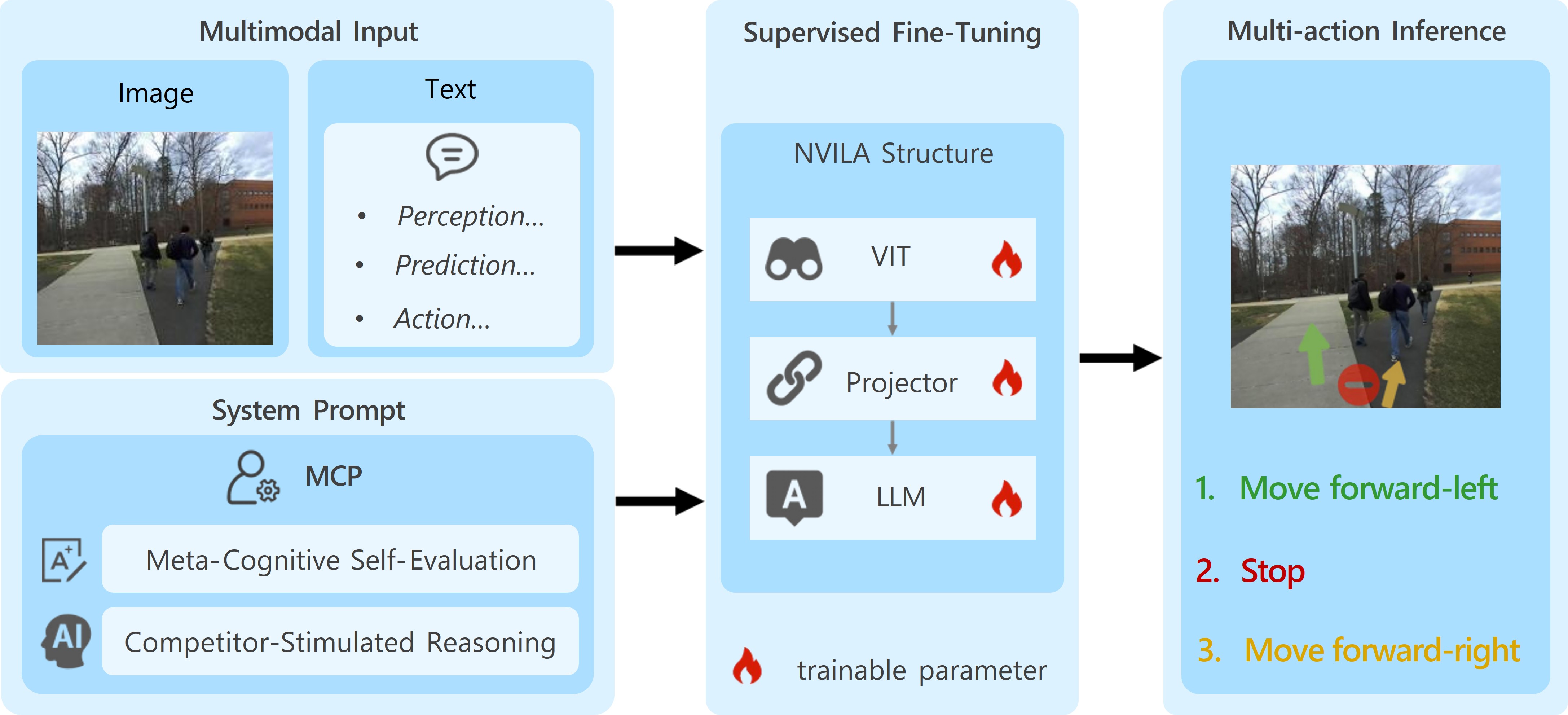
Fig. 1. Detailed pipeline of the proposed MAction-SocialNav model. -
E-SocialNav: Efficient Socially Compliant Navigation with Language Models
,
L. Xiao, D. Song, X. Xiao, and T. Yamasaki,
2026 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), pp. 20077-20081, 2026.
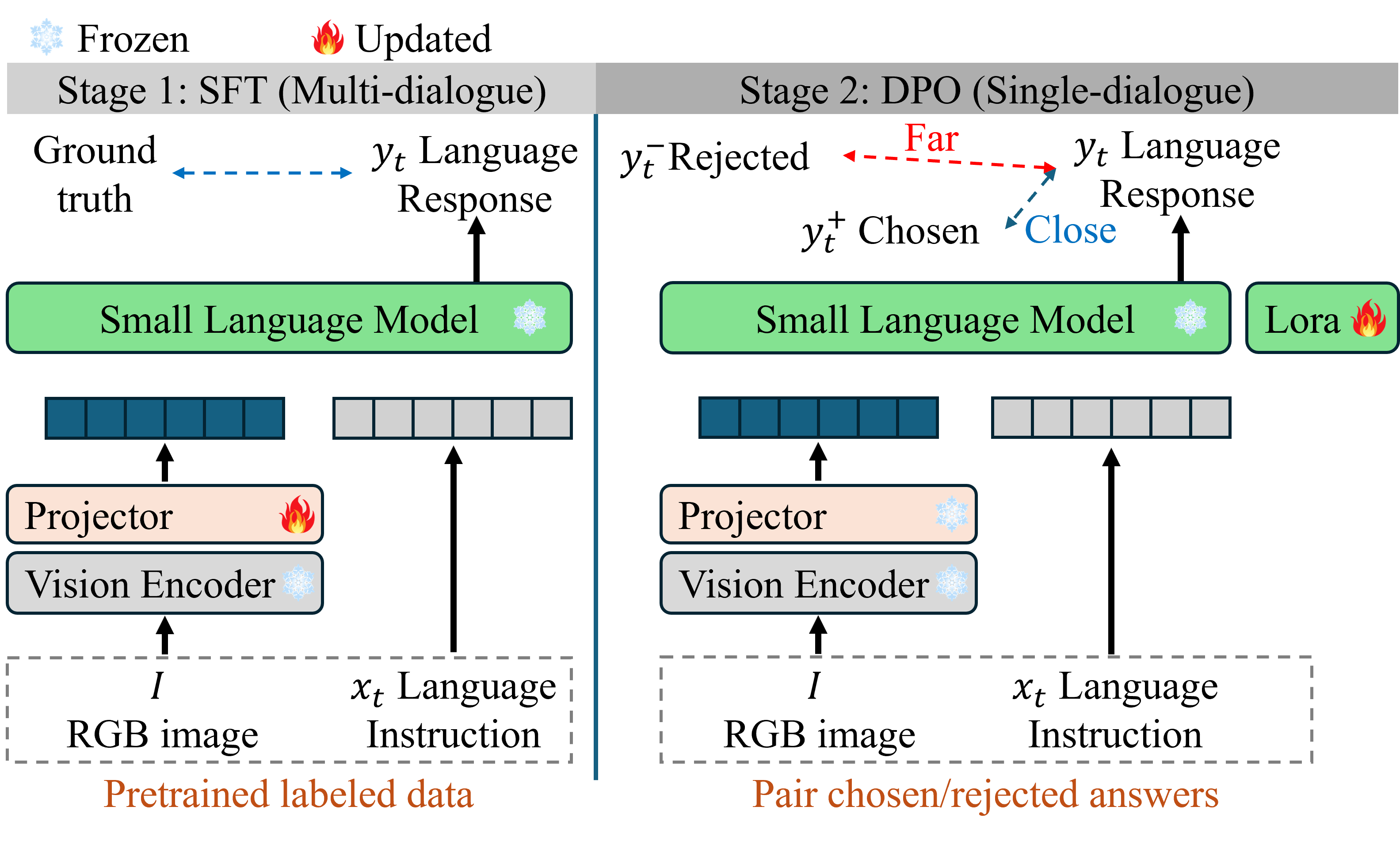
Fig. 1. The detailed structure of E-SocialNav. 
Fig. 2. Visualizations: E-SocialNav accurately captures social-compliance cues from the image.
International Conferences (Peer-reviewed, *Corresponding Author)
- SOPD-SocialNav: Selective On-Policy Distillation for Vision-Language Social Navigation, X. Zhang, Z. Wang, and L. Xiao*, 2026 WRC Symposium on Advanced Robotics and Automation (WRC SARA) (WRC SARA 2026), accepted, 2026.
- HumAIN: Human-Aware Implicit Social Robot Navigation, D. Song, N. Le, J. Chen, M. Nazeri, A. Payandeh, R. Chandra, R. Mirsky, R. Mead, L. Xiao, X. Xiao, 2026 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (IROS 2026), accepted, 2026.
- Deconstructing the Failure of Ideal Noise Correction: A Three-Pillar Diagnosis, C. Feng, Z. Zhi, Z. Huang, J. Ge, L. Xiao, N. Sebe, G. Tzimiropoulos, I. Patras, The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 34512-34523, 2026.
- LLM Guided Multi Style Typography and Layout Generation via Dynamic Direct Preference Optimization, C. FU, S. Yi, L. Xiao, T. Yamasaki, The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Findings, pp. 5725-5734, 2026.
- E-SocialNav: Efficient Socially Compliant Navigation with Language Models, L. Xiao D. Song, X. Xiao, and T. Yamasaki, 2026 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), pp. 20077-20081, 2026.
- A Personalized Language-Guided Video Summarization System Using Text Semantic Matching, T. Sugihara, S. Masuda, L. Xiao*, and T. Yamasaki, The IEEE/CVF Winter Conference on Applications of Computer Vision (WACV 2026) , accepted [Demo], 2026.
- Incorporating Semantic Visual Content into Click-Through Rate Prediction for Video Advertisements, Y. Tanabe, S. Masuda, G. Ryu, N. Tanji, H. Seshime, L. Xiao, and T. Yamasaki, The 17th Asia Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC 2025), pp. 1916-1921, 2025.
- Combining Non-Numerical Text and Numerical Sequences in LLM-based Survival Prediction, Z. Zhou, G. Qian, X. Jiang, G. Wang, R. Lu, L. Xiao, and S. Tang, The 22nd Pacific Rim International Conference Series on Artificial Intelligence (PRICAI 2025), pp. 256-271, 2025.
- ActRecognition-GPT: Utilizing Multimodal Large Language Models for Spatiotemporal Action Recognition in Nursery Videos, K. Watanabe, S. Masuda, L. Xiao, and T. Yamasaki, FM&LLM&GM 2025 (FG 2025 Workshop), pp. 1–10, 2025.
- TourMLLM: A Retrieval-Augmented Multimodal Large Language Model for Multitask Learning in the Tourism Domain, H. Yamanishi, L. Xiao* (corresponding author), and T. Yamasaki, ACM ICMR, pp. 1654–1663, 2025, Best paper award! News page!
- Explainable AI for Image Aesthetic Evaluation Using Vision-Language Models, S. Viriyavisuthisakul, S.n Yoshida, K. Shiohara, L. Xiao, and T. Yamasaki, AIxMM, pp. 62–65, 2025.
- LITA: LMM-guided Image-Text Alignment for Art Assessment, T. Sunada, K. Shiohara, L. Xiao, and T. Yamasaki, MMM 2025, pp. 268–281, 2025.
- Language-Guided Self-Supervised Video Summarization Using Text Semantic Matching Considering the Diversity of the Video, T. Sugihara, S. Masuda, L. Xiao*, and T. Yamasaki, ACM Multimedia Asia 2024, p. 1, 2024. [Code]
- LLaVA-Tour: A Large-Scale Multimodal Model Specializing in Japanese Tourist Spot Prediction and Review Generation, H. Yamanishi, L. Xiao*, and T. Yamasaki, VCIP 2024, pp. 1–5, 2024. [Best Paper Candidate] [Code]
- A Multimodal Dataset and Benchmark for Tourism Review Generation, H. Yamanishi, L. Xiao*, and T. Yamasaki, ACM RecSys Workshop on Recommenders in Tourism (RecTour 2024), Vol. 3886, pp. 49–67, 2024.
- SCOMatch: Alleviating Overtrusting in Open-set Semi-supervised Learning, Z. R. Wang, L. Y. Xiang, L. Huang, J. F. Mao, L. Xiao, and T. Yamasaki, ECCV 2024, pp. 217–233, 2024.
- Adversarially Robust Continual Learning with Anti-forgetting Loss, K. Mukai, S. Kumano, N. Michel, L. Xiao, and T. Yamasaki, ICIP 2024, pp. 1085–1091, 2024.
- E-ReaRev: Adaptive Reasoning for Question Answering over Incomplete Knowledge Graphs by Edge and Meaning Extensions, X.T. Ye, L. Xiao, C. Zhang, and T. Yamasaki, NLDB 2024, pp. 85–95, 2024.
- Rethinking Momentum Knowledge Distillation in Online Continual Learning, N. Michel, M. Wang, L. Xiao, and T. Yamasaki, ICML 2024, pp. 35607–35622, 2024. [Code]
- Boosting Fine-grained Fashion Retrieval with Relational Knowledge Distillation, L. Xiao and T. Yamasaki, CVPR 2024 Workshop (CVFAD), pp. 8229–8234, 2024. [Code]
- Improving Plasticity in Online Continual Learning via Collaborative Learning, M. Wang, N. Michel, L. Xiao, and T. Yamasaki, CVPR 2024, pp. 23460–23469, 2024. [Code]
- HetSpot: Analyzing Tourist Spot Popularity with Heterogeneous Graph Neural Network, H. Yamanishi, L. Xiao*, and T. Yamasaki, IVSP 2024, pp. 111–120, 2024.
- Toward a More Robust Fine-grained Fashion Retrieval, L. Xiao, X. F. Zhang, and T. Yamasaki, MIPR 2023, pp. 1–4, 2023. [Code]
- Learning Fashion Compatibility with Color Distortion Prediction, L. Xiao, X. F. Zhang, and T. Yamasaki, MIPR 2023, pp. 81–84, 2023.
- Bridging the Capacity Gap for Online Knowledge Distillation, M. Wang, H. Yu, L. Xiao, and T. Yamasaki, MIPR 2023, pp. 1–4, 2023. [Code]
- SAT: Self-adaptive Training for Fashion Compatibility Prediction, L. Xiao and T. Yamasaki, ICIP 2022, pp. 2431–2435, 2022.
- Surface Defect Detection Using Hierarchical Features, L. Xiao, T. Huang, B. Wu, Y. Hu, and J. Zhou, CASE 2019, pp. 1592–1596, 2019.
- A Remote Health Condition Monitoring System Based on Compressed Sensing, J. Liu, Y. Hu, Y. Lu, Y. Wang, L. Xiao, and K. Zheng, MSCE 2017, pp. 262–266, 2017.
International Journals (Peer-reviewed, *Corresponding Author)
- MAction-SocialNav: Multi-Action Socially Compliant Navigation via Reasoning-enhanced Prompt Tuning, Z. Wang, X. Zhang, Z. Liu, T. Kawabata, D. Song, X. Xiao, and L. Xiao*, IEEE Robotics and Automation Letters (RA-L), vol. 11, no. 8, pp. 9747-9754, 2026.
- A Multihead Continual Learning Framework for Fine-Grained Fashion Image Retrieval with Contrastive Learning and Exponential Moving Average Distillation, L. Xiao and T. Yamasaki, IEEE Transactions on Multimedia, pp. 1-10, 2026.
- Language-Guided Frameworks for Personalized Video Summarization, T. Sugihara, S. Masuda, L. Xiao and T. Yamasaki, Pattern Analysis and Applications, vol. 29(3), p.123, 2026. [Code]
- GeoDCL: Weak Geometrical Distortion based Contrastive Learning for Fine-grained Fashion Image Retrieval, L. Xiao and T. Yamasaki, IEEE Transactions on Artificial Intelligence, vol. 1, pp. 1–13, 2025.
- Multi-level Knowledge Distillation for Fine-grained Fashion Image Retrieval, L. Xiao and T. Yamasaki, Knowledge-Based Systems, vol. 310, p. 112955, 2025.
- LiFSO-Net: A Lightweight Feature Screening Optimization Network for Complex-scale Flat Metal Defect Detection, Hao Zhong, L. Xiao, Haifeng Wang, Xin Zhang, Chenhui Wan, and Bo Wu, Knowledge-Based Systems, vol. 304, p. 112520, 2024.
- Attribute-Guided Multi-Level Attention Network for Fine-Grained Fashion Retrieval, L. Xiao and T. Yamasaki, IEEE Access, vol. 12, pp. 48068–48080, 2024. [Code]
- STFE-Net: A Multi-stage Approach to Enhance Statistical Texture Feature for Defect Detection on Metal Surfaces, H. Zhong, D. X. Fu, L. Xiao, F. Zhao, J. Liu, B. Wu, and Y. M. Hu, Advanced Engineering Informatics, vol. 61, p. 102437, 2024.
- Missing Small Fastener Detection Using Deep Learning, L. Xiao, B. Wu, and Y. Hu, IEEE Transactions on Instrumentation and Measurement, vol. 70, pp. 1–9, 2020.
- OSED: Object-specific Edge Detection, L. Xiao, B. Wu, and Y. Hu, Journal of Visual Communication and Image Representation, vol. 72, p. 102918, 2020.
- Detection of Powder Bed Defects in Selective Laser Sintering Using Convolutional Neural Network, L. Xiao, M. Lu, and H. Huang, International Journal of Advanced Manufacturing Technology, vol. 107, pp. 2485–2496, 2020.
- A Hierarchical Features-based Model for Freight Train Defect Inspection, L. Xiao, B. Wu, Y. Hu, and J. Liu, IEEE Sensors Journal, vol. 20(5), pp. 2671–2678, 2019.
- Surface Defect Detection Using Image Pyramid, L. Xiao, B. Wu, and Y. Hu, IEEE Sensors Journal, vol. 20(13), pp. 7181–7188, 2020.
arXiv Papers (*Corresponding Author)
- Vision-Language Models for Deployable Social Robot Navigation: Bridging Semantic Reasoning and Low-Level Control, R. Cai, T. Yamasaki, and L. Xiao*, arXiv:2606.28760, 2026.
- Enhancing Lightweight Vision Language Models through Group Competitive Learning for Socially Compliant Navigation, X. Zhang, A. Konno, T. Yamasaki, and L. Xiao*, arXiv:2603.11447, 2026.
- Spectral Probing of Feature Upsamplers in 2D-to-3D Scene Reconstruction, L. Xiao Y. Xiu, Y. Chen, G. Wang, and T. Yamasaki, arXiv:2603.05787, 2026.
- Probing Prompt Design for Socially Compliant Robot Navigation with Vision Language Models, L. Xiao and T. Yamasaki, arXiv:2601.14622, 2026.
- MUSON: A Reasoning-oriented Multimodal Dataset for Socially Compliant Navigation in Urban Environments, Z. Liu, X. Zhang, Z. Wang, T. Kawabata, X. Xiao, and L. Xiao*, arXiv:2512.22867, 2025. [MUSON Dataset]
- MAction-SocialNav: Multi-Action Socially Compliant Navigation via Reasoning-enhanced Prompt Tuning, Z. Wang, X. Zhang, Z. Liu, T. Kawabata, D. Song, X. Xiao, and L. Xiao*, arXiv:2512.21722, 2025.
- SocialNav-MoE: A Mixture-of-Experts Vision Language Model for Socially Compliant Navigation with Reinforcement Fine-Tuning, T. Kawabata, X.Y. Zhang, and L. Xiao*, arXiv:2512.14757, 2025.
- LLM-Advisor: An LLM Benchmark for Cost-efficient Path Planning across Multiple Terrains, L. Xiao and T. Yamasaki, arXiv:2503.01236, 2025.
- Language-Guided Self-Supervised Video Summarization Using Text Semantic Matching Considering the Diversity of the Video, T. Sugihara, S. Masuda, L. Xiao, and T. Yamasaki, arXiv:2405.08890, 2024.
- Rethinking Momentum Knowledge Distillation in Online Continual Learning, N. Michel, M. Wang, L. Xiao, and T. Yamasaki, arXiv:2309.02870, 2023.
- Online Open-set Semi-supervised Object Detection via Semi-supervised Outlier Filtering, Z. Wang, L. Xiao, L. Xiang, Z. Weng, and T. Yamasaki, arXiv:2305.13802, 2023.
- MetaMixer: A Regularization Strategy for Online Knowledge Distillation, M. Wang, L. Xiao, and T. Yamasaki, arXiv:2303.07951, 2023.
- Semi-supervised Fashion Compatibility Prediction by Color Distortion Prediction, L. Xiao and T. Yamasaki, arXiv:2212.14680, 2022.
- Attribute-Guided Multi-Level Attention Network for Fine-Grained Fashion Retrieval, L. Xiao and T. Yamasaki, arXiv:2301.13014, 2022.
Domestic Conferences (Some)
- A Multimodal Dataset for Socially Compliant Navigation in Urban Environments, Zhuonan Liu, Zishuo Wang, Xinyu Zhang, Tomohito Kawabata, Ling Xiao, 信学技報 , vol. 125, no. 356, IE2025-63, pp. 49-54, 2026年2月. [IE賞]
- Enhancing the Spatial Awareness of Large Language Models in Path Planning, Ling Xiao and Toshihiko Yamasaki, 第30回 知能メカトロニクスワークショップ 2025 (iMec), 2025.
- Few-shot推論によるアノテータに個人適応可能なビデオ要約, 杉原朋弥, 増田俊太郎, 肖玲, 山崎俊彦, MIRU 2025, IS3-102, 2025.
- 時空間情報を統合したプロンプトを用いた保育施設映像の行動認識, 渡辺健太, 増田俊太郎, 肖玲, 山崎俊彦, MIRU 2025, IS2-081, 2025.
- LLM-Advisor: Leveraging LLMs as Advisors for Cost-efficient Path Planning Across Diverse Terrains, Ling Xiao and Toshihiko Yamasaki, MIRU 2025, IS2-185, 2025.
- TourMLLM: 検索拡張大規模観光マルチモーダルモデル, 山西博雅, Ling Xiao, 山崎俊彦, MIRU 2025, IS2-119, 2025.
- 基盤モデルによる視覚的評価を用いた動画広告の効果分析, 田邉克晃, 増田俊太郎, 劉岳松, 丹治直人, 勢〆弘幸, 肖玲, 山崎俊彦, MIRU 2025, OS2C-06, 2025. [Oral]
- Content-Aware Layout Generation with Large Language Models, Chen FU, Naoto Tanji, Gakumatsu Ryu, Hiroyuki SESHIME, Shengzhou Yi, Ling Xiao, and Toshihiko Yamasaki, MIRU 2025, IS1-102, 2025.
- タスク適応的検索拡張学習に基づく観光特化大規模マルチモーダルモデル, 山西博雅, 肖 玲, 山崎俊彦, 信学技報, 画像工学研究会 (IE), IE2024-61.
- Explainable Image Aesthetic Assessment Leveraging Vision-Language Models, S. Viriyavisuthisakul, S.n Yoshida, K. Shiohara, L. Xiao, and T. Yamasaki, 信学技報, 画像工学研究会 (IE), IE2024-66.
- Momentum Knowledge Distillation for Enhanced Online Continual Learning, N. Michel, M. Wang, L. Xiao, and T. Yamasaki, 信学技報, 画像工学研究会 (IE), IE2024-57.
- Llava-Planner: Enhancing Spatial Awareness of LLaVA for Cost-Effective Path Planning, L. Xiao, H. Yamanishi, and T. Yamasaki, 信学技報, 画像工学研究会 (IE), IE2024-44.
- LLM-Advisor: A LLM Benchmark for Cost-effective Path Planning, L. Xiao and T. Yamasaki, PCSJ/IMPS 2024, P-2-05, 2024.
- マルチモーダル観光レビュー生成データセットと大規模レビュー生成モデルの作成, H. Yamanishi, L. Xiao, and T. Yamasaki, PCSJ/IMPS 2024, P-4-18, 2024.
- Boosting Fine-grained Fashion Retrieval with Relational Knowledge Distillation, L. Xiao and T. Yamasaki, 信学技報, 画像工学研究会 (IE), vol. 124, no. 60, IE2024-17, pp. 90–94, 2024. [Code]
- Language-Guided Self-Supervised Video Summarization Using Text Semantic Matching, T. Sugihara, S. Masuda, L. Xiao, and T. Yamasaki, MIRU 2024. [Oral]
- 大規模マルチモーダルモデルを用いた広告画像の評価・改善, 砂田達巳, 塩原楓, 劉岳松, 丹治直人, 勢〆弘幸, 肖玲, 山崎俊彦, MIRU 2024. [Oral]
- Multi-hop Question Answering over Incomplete Knowledge Graphs by Edge and Meaning Extensions, X.T. Ye, L. Xiao, C. Zhang, and T. Yamasaki, MIRU 2024.
- Constrianed Advertisement Layout Generation based on Graph Neural Networks, C. Fu, Y. Liu, N. Tanji, H. Seshime, L. Xiao, and T. Yamasaki, MIRU 2024.
- Improving Adversarial Robustness in Continual Learning, K. Mukai, S. Kumano, N. Michel, L. Xiao, and T. Yamasaki, 信学技報, 画像工学研究会 (IE), vol. 123, no. 381, IE2023-37, pp. 13–18, 2024. [IE賞]
- 大規模言語モデルを活用した自己教師あり学習によるビデオ要約, 杉原朋弥, 増田俊太郎, 肖玲, 山崎俊彦, IPSJ, 7T-06, pp. 2-653–2-654, 2024.
- Advertisement Layout Generation based on Graph Neural Network, C. Fu, Y. Liu, N. Tanji, H. Seshime, L. Xiao, and T. Yamasaki, 信学技報, 画像工学研究会 (IE), vol. 123, no. 381, IE2023-51, pp. 88–89, 2024.
- Improved Fine-grained Fashion Retrieval with Contrastive Learning, L. Xiao, X. F. Zhang, and T. Yamasaki, MIRU 2023, IS3-55, 2023.
- Video Summarization Based on Masked Autoencoder, M. L. A. FOK, L. Xiao, and T. Yamasaki, MIRU 2023, IS1-84, 2023.
- Improving Fashion Compatibility Prediction with Color Distortion Prediction, L. Xiao and T. Yamasaki, 信学技報, 画像工学研究会 (IE), vol. 122, no. 385, IE2022-61, pp. 17–18, 2023.
- Multi-Level Attention Network for Fine-Grained Fashion Retrieval, L. Xiao and T. Yamasaki, 信学技報, MVE, vol. 122, no. 440, MVE2022-90, pp. 198–199, 2023.
- SAT: Self-adaptive Training for Fashion Compatibility Prediction, L. Xiao and T. Yamasaki, MIRU 2022.
- Spatial Attention Based Fashion Compatibility Prediction, L. Xiao and T. Yamasaki, PCSJ/IMPS 2021, P-3-17, pp. 135–136, 2021.
Patents (China)
- 一种用于静脉穿刺的穿刺靶点识别与定位方法, 肖玲、欧阳浩、叶霖、韩斌、陈学东、杨新 (发明专利,专利号: 202210202422.1,申请中)
- 一种钢卷双目视觉定位方法及设备, 胡友民、肖玲、吴波 (发明专利,专利号: 201810094718.X,授权日:2020.09.18)
- 一种基于视觉的钢卷定位方法及设备, 胡友民、肖玲、吴波 (发明专利,专利号: 201811059328.5,授权日:2020.07.10)
- 一种可视化的起重机吊取定位系统, 胡友民、肖玲、吴波、刘颉 (发明专利,专利号: 201611246219.5,授权日:2018.01.02)
- 一种焊接熔池动态过程的在线监测系统及方法, 胡友民、刘颉、肖玲、唐松、谷勇 (发明专利,专利号: 201610288460.8,授权日:2018.06.12)
- 一种用于焊接熔池在线监测平台的多功能夹具, 胡友民、唐松、肖玲、谷勇、刘颉 (实用新型专利,专利号: 201620434683.6,授权日:2016.10.05)
- 一种针对光流图的快速的FCM图像分割方法, 胡友民、胡中旭、吴波、武敏健、刘颉、肖玲、王诗杰、李雪莲 (发明专利,专利号: 201710530461.3,授权日:2019.11.12) (2023年度湖北省科学技术奖提名)